Benchmarking full and chunked file reading
Benchmarking full and chunked file reading#
In this notebook, a benchmark on three file types (DAT, EVT2 and EVT3) is run
from expelliarmus import Wizard
import pathlib
import h5py
import numpy as np
import timeit
import requests
import pickle
FIRST_RUN = True
SAVE_RESULTS = True
LOAD_RESULTS = False
REPEAT = 10
def get_diff_perc_str(ref, val):
if (val > ref):
return f"+{round((val/ref-1)*100)}%"
else:
return f"-{round((1-val/ref)*100)}%"
get_fsize_MB = lambda fpath: round(fpath.stat().st_size/(1024*1024))
fname = "driving_sample"
get_fpath = lambda encoding: f"{fname}_{encoding}.{'raw' if encoding!='dat' else 'dat'}"
if FIRST_RUN:
# Downloading files.
print("Downloading EVT3 file... ", end="")
if not pathlib.Path(get_fpath('evt3')).is_file():
r = requests.get("https://dataset.prophesee.ai/index.php/s/nVcLLdWAnNzrmII/download", allow_redirects=True) # spinner.dat, DAT
open(get_fpath('evt3'), 'wb').write(r.content)
print("done!")
Downloading EVT3 file... done!
softwares = ("hdf5", "hdf5_lzf", "hdf5_gzip", "numpy")
encodings = ("dat", "evt2", "evt3")
print("Converting the EVT3 file to EVT2 and DAT formats... ", end="")
wizard = Wizard(encoding="evt3")
evt3_arr = wizard.read(get_fpath('evt3'))
for encoding in ("dat", "evt2"):
wizard.set_encoding(encoding)
wizard.save(fpath=get_fpath(encoding), arr=evt3_arr)
print("done!")
Converting the EVT3 file to EVT2 and DAT formats... done!
data = dict(
expelliarmus=dict(dat=dict(fsize=0, full=0, windowed=0, chunked=0),
evt2=dict(fsize=0, full=0, windowed=0, chunked=0),
evt3=dict(fsize=0, full=0, windowed=0, chunked=0),
),
hdf5=dict(fsize=0, full=0, windowed=0, chunked=0),
hdf5_lzf=dict(fsize=0, full=0, windowed=0, chunked=0),
hdf5_gzip=dict(fsize=0, full=0, windowed=0, chunked=0),
numpy=dict(fsize=0, full=0),
)
if LOAD_RESULTS:
data = pickle.load(open("./benchmark.pk", "rb"))
print("Full file read")
for encoding in encodings:
if not LOAD_RESULTS:
fpath = pathlib.Path(get_fpath(encoding))
wizard.set_encoding(encoding)
wizard.set_file(fpath)
if FIRST_RUN:
arr = wizard.read()
data["expelliarmus"][encoding]["fsize"] = get_fsize_MB(fpath)
data["expelliarmus"][encoding]["full"] = sum(timeit.repeat(lambda: wizard.read(), number=1, repeat=REPEAT))/REPEAT
# HDF5 formats.
if FIRST_RUN:
for sw in softwares[:-1]:
fpath = pathlib.Path(f"ref_{sw}.hdf5")
fp = h5py.File(fpath, "w")
if sw=="hdf5":
arr_hdf5 = fp.create_dataset("arr", arr.shape, arr.dtype)
elif sw=="hdf5_lzf":
arr_hdf5 = fp.create_dataset("arr", arr.shape, arr.dtype, compression="lzf")
elif sw=="hdf5_gzip":
arr_hdf5 = fp.create_dataset("arr", arr.shape, arr.dtype, compression="gzip")
arr_hdf5[:] = arr[:]
fp.close()
data[sw]["fsize"] = get_fsize_MB(fpath)
fp = h5py.File(fpath)
data[sw]["full"] = sum(timeit.repeat(lambda: fp["arr"][:], number=1, repeat=REPEAT))/REPEAT
fp.close()
# NumPy
fpath = pathlib.Path("ref_np.npy")
np.save(fpath, arr, allow_pickle=False)
data["numpy"]["fsize"] = get_fsize_MB(fpath)
data["numpy"]["full"] = sum(timeit.repeat(lambda: np.load(fpath), number=1, repeat=REPEAT))/REPEAT
# Printing results.
def get_spacing (header, printed):
if isinstance(printed, float):
return " "*(len(header)+1 - len(f"{printed:.3f}"))
else:
return " "*(len(header)+1 - len(str(printed)))
def gen_row(sw_name, size_value, time_value, mode):
exp_dict = data["expelliarmus"]
dat_fsize, evt2_fsize, evt3_fsize = exp_dict["dat"]["fsize"], exp_dict["evt2"]["fsize"], exp_dict["evt3"]["fsize"]
dat_time, evt2_time, evt3_time = exp_dict["dat"][mode], exp_dict["evt2"][mode], exp_dict["evt3"][mode]
return f'{sw_name}{get_spacing("Software ", sw_name)}| \
{size_value}{get_spacing("Size [MB]", size_value)}| \
{get_diff_perc_str(dat_fsize, size_value)}{get_spacing("Diff. DAT", get_diff_perc_str(dat_fsize, size_value))}| \
{get_diff_perc_str(evt2_fsize, size_value)}{get_spacing("Diff. EVT2", get_diff_perc_str(evt2_fsize, size_value))}| \
{get_diff_perc_str(evt3_fsize, size_value)}{get_spacing("Diff. EVT3", get_diff_perc_str(evt3_fsize, size_value))}| \
{time_value:.2f}{get_spacing("Time [s]", time_value)}| \
{get_diff_perc_str(dat_time, time_value)}{get_spacing("Diff. DAT", get_diff_perc_str(dat_time, time_value))}| \
{get_diff_perc_str(evt2_time, time_value)}{get_spacing("Diff. EVT2", get_diff_perc_str(evt2_time, time_value))}| \
{get_diff_perc_str(evt3_time, time_value)}{get_spacing("Diff. EVT3", get_diff_perc_str(evt3_time, time_value))}'
header = f"Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3"
print("-"*len(header))
print(header)
print("-"*len(header))
for encoding in encodings:
print(gen_row(f"exp. {encoding.upper()}", data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["full"], "full"))
print("-"*len(header))
for sw in softwares:
print(gen_row(sw, data[sw]["fsize"], data[sw]["full"], "full"))
print("-"*len(header))
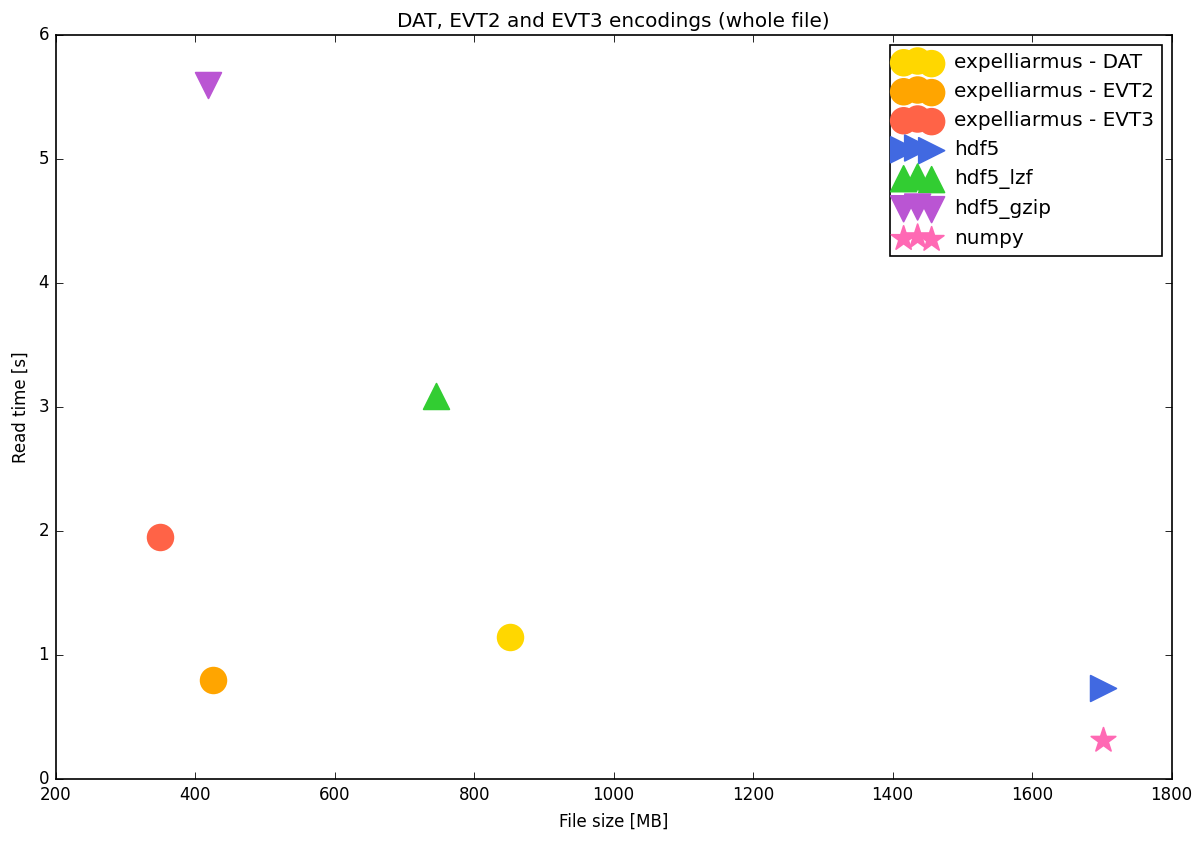
Full file read
------------------------------------------------------------------------------------------------------------
Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3
------------------------------------------------------------------------------------------------------------
exp. DAT | 851 | -0% | +100% | +143% | 1.15 | -0% | +43% | -41%
------------------------------------------------------------------------------------------------------------
exp. EVT2 | 426 | -50% | -0% | +22% | 0.80 | -30% | -0% | -59%
------------------------------------------------------------------------------------------------------------
exp. EVT3 | 350 | -59% | -18% | -0% | 1.95 | +70% | +144% | -0%
------------------------------------------------------------------------------------------------------------
hdf5 | 1701 | +100% | +299% | +386% | 0.73 | -36% | -8% | -62%
------------------------------------------------------------------------------------------------------------
hdf5_lzf | 746 | -12% | +75% | +113% | 3.09 | +170% | +287% | +58%
------------------------------------------------------------------------------------------------------------
hdf5_gzip | 419 | -51% | -2% | +20% | 5.60 | +389% | +600% | +187%
------------------------------------------------------------------------------------------------------------
numpy | 1701 | +100% | +299% | +386% | 0.32 | -72% | -60% | -84%
------------------------------------------------------------------------------------------------------------
import matplotlib.pyplot as plt
import matplotlib as mpl
plt.style.use('classic')
%matplotlib inline
plt.clf()
fig = plt.figure(figsize=(12, 8), dpi=120)
plt.xlabel("File size [MB]")
plt.ylabel("Read time [s]")
plt.title("DAT, EVT2 and EVT3 encodings (whole file)")
exp_colors = dict(dat="gold", evt2="orange", evt3="tomato")
sw_colors = dict(hdf5="royalblue", hdf5_lzf="limegreen", hdf5_gzip="mediumorchid", numpy="hotpink")
sw_markers = dict(hdf5=">", hdf5_lzf="^", hdf5_gzip="v", numpy="*")
# Expelliarmus
for encoding in encodings:
plt.scatter(data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["full"], marker="o", s=240, color=exp_colors[encoding], label=f"expelliarmus - {encoding.upper()}")
# Other softwares.
for sw in softwares:
plt.scatter(data[sw]["fsize"], data[sw]["full"], marker=sw_markers[sw], s=240, color=sw_colors[sw], label=sw)
plt.legend()
plt.show()
<Figure size 432x288 with 0 Axes>
TIME_WINDOW = 20
print("Time windowing read")
arr_len = len(wizard.read(get_fpath("evt3")))
for encoding in encodings:
if not LOAD_RESULTS:
fpath = pathlib.Path(get_fpath(encoding))
wizard.set_encoding(encoding)
wizard.set_file(fpath)
wizard.set_time_window(TIME_WINDOW)
time_window_length = len(next(wizard.read_time_window()))
def fn():
wizard.reset()
return [window for window in wizard.read_time_window()]
data["expelliarmus"][encoding]["windowed"] = sum(timeit.repeat(fn, number=1, repeat=REPEAT))/REPEAT
# HDF5 formats.
for sw in softwares[:-1]:
fpath = pathlib.Path(f"ref_{sw}.hdf5")
fp = h5py.File(fpath)
data[sw]["windowed"] = sum(timeit.repeat(lambda: [fp["arr"][i*time_window_length:min(arr_len, (i+1)*time_window_length)] for i in range(arr_len//time_window_length)], number=1, repeat=REPEAT))/REPEAT
fp.close()
header = f"Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3"
print("-"*len(header))
print(header)
print("-"*len(header))
for encoding in encodings:
print(gen_row(f"exp. {encoding.upper()}", data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["windowed"], "windowed"))
print("-"*len(header))
for sw in softwares[:-1]:
print(gen_row(sw, data[sw]["fsize"], data[sw]["windowed"], "windowed"))
print("-"*len(header))
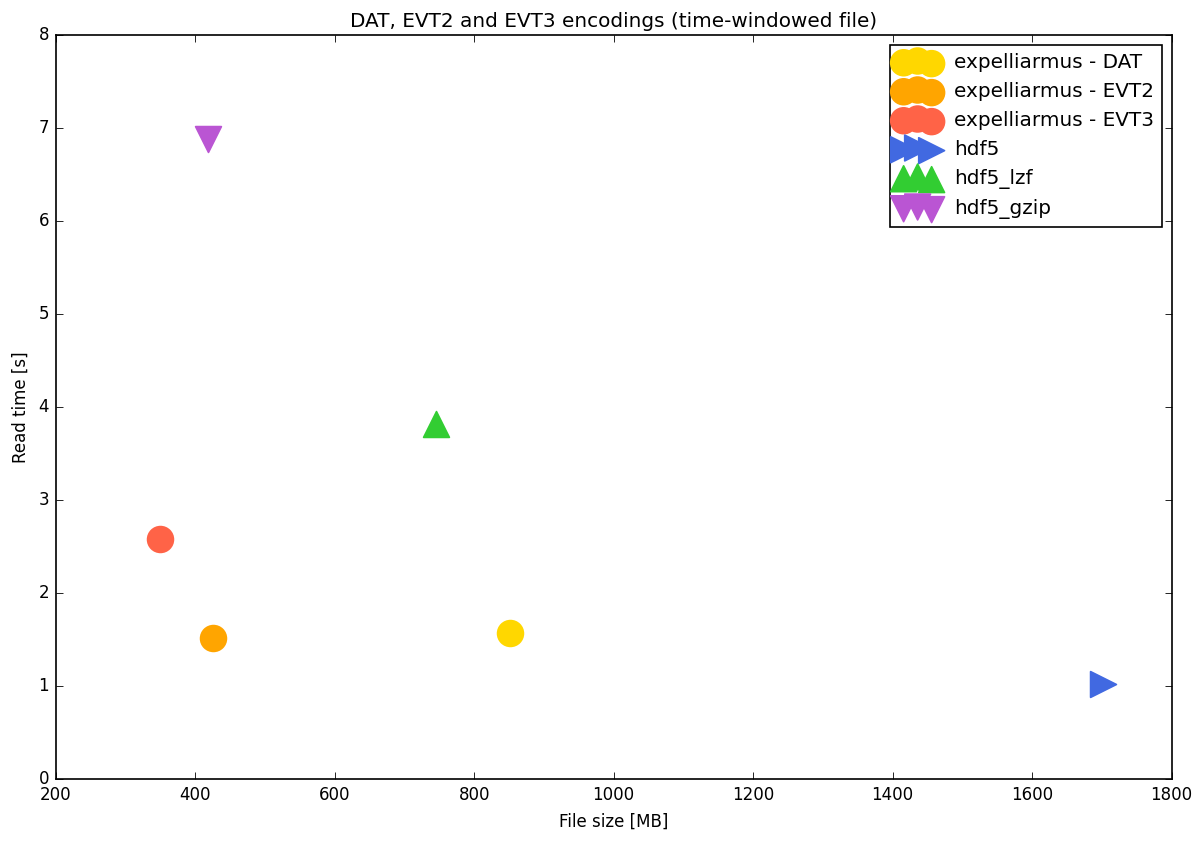
Time windowing read
------------------------------------------------------------------------------------------------------------
Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3
------------------------------------------------------------------------------------------------------------
exp. DAT | 851 | -0% | +100% | +143% | 1.58 | -0% | +4% | -39%
------------------------------------------------------------------------------------------------------------
exp. EVT2 | 426 | -50% | -0% | +22% | 1.51 | -4% | -0% | -42%
------------------------------------------------------------------------------------------------------------
exp. EVT3 | 350 | -59% | -18% | -0% | 2.58 | +64% | +71% | -0%
------------------------------------------------------------------------------------------------------------
hdf5 | 1701 | +100% | +299% | +386% | 1.02 | -35% | -32% | -60%
------------------------------------------------------------------------------------------------------------
hdf5_lzf | 746 | -12% | +75% | +113% | 3.82 | +143% | +153% | +48%
------------------------------------------------------------------------------------------------------------
hdf5_gzip | 419 | -51% | -2% | +20% | 6.88 | +337% | +355% | +166%
------------------------------------------------------------------------------------------------------------
plt.clf()
fig = plt.figure(figsize=(12, 8), dpi=120)
plt.xlabel("File size [MB]")
plt.ylabel("Read time [s]")
plt.title("DAT, EVT2 and EVT3 encodings (time-windowed file)")
# Expelliarmus
for encoding in encodings:
plt.scatter(data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["windowed"], marker="o", s=240, color=exp_colors[encoding], label=f"expelliarmus - {encoding.upper()}")
# Other softwares.
for sw in softwares[:-1]:
plt.scatter(data[sw]["fsize"], data[sw]["windowed"], marker=sw_markers[sw], s=240, color=sw_colors[sw], label=sw)
plt.legend()
plt.show()
<Figure size 432x288 with 0 Axes>
CHUNK_LEN = 8192
print("Chunk read")
arr_len = len(wizard.read(get_fpath("evt3")))
for encoding in encodings:
if not LOAD_RESULTS:
fpath = pathlib.Path(get_fpath(encoding))
wizard.set_encoding(encoding)
wizard.set_file(fpath)
wizard.set_chunk_size(CHUNK_LEN)
def fn():
wizard.reset()
return [chunk for chunk in wizard.read_chunk()]
data["expelliarmus"][encoding]["chunked"] = sum(timeit.repeat(fn, number=1, repeat=REPEAT))/REPEAT
# HDF5 formats.
for sw in softwares[:-1]:
fpath = pathlib.Path(f"ref_{sw}.hdf5")
fp = h5py.File(fpath)
data[sw]["chunked"] = sum(timeit.repeat(lambda: [fp["arr"][i*CHUNK_LEN:min(arr_len, (i+1)*CHUNK_LEN)] for i in range(arr_len//CHUNK_LEN)], number=1, repeat=REPEAT))/REPEAT
fp.close()
header = f"Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3"
print("-"*len(header))
print(header)
print("-"*len(header))
for encoding in encodings:
print(gen_row(f"exp. {encoding.upper()}", data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["chunked"], "chunked"))
print("-"*len(header))
for sw in softwares[:-1]:
print(gen_row(sw, data[sw]["fsize"], data[sw]["chunked"], "chunked"))
print("-"*len(header))
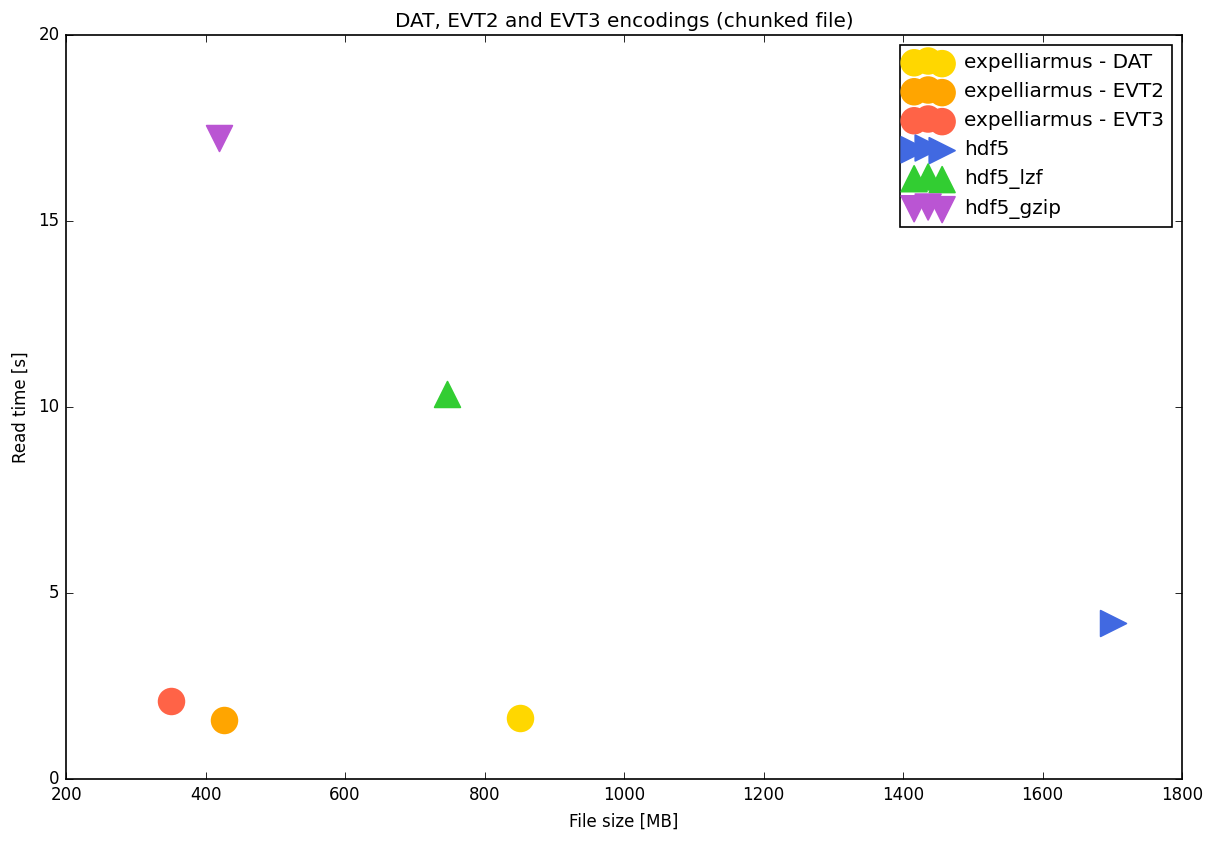
Chunk read
------------------------------------------------------------------------------------------------------------
Software | Size [MB] | Diff. DAT | Diff. EVT2 | Diff. EVT3 | Time [s] | Diff. DAT | Diff. EVT2 | Diff. EVT3
------------------------------------------------------------------------------------------------------------
exp. DAT | 851 | -0% | +100% | +143% | 1.64 | -0% | +3% | -22%
------------------------------------------------------------------------------------------------------------
exp. EVT2 | 426 | -50% | -0% | +22% | 1.58 | -3% | -0% | -24%
------------------------------------------------------------------------------------------------------------
exp. EVT3 | 350 | -59% | -18% | -0% | 2.09 | +28% | +32% | -0%
------------------------------------------------------------------------------------------------------------
hdf5 | 1701 | +100% | +299% | +386% | 4.20 | +157% | +166% | +101%
------------------------------------------------------------------------------------------------------------
hdf5_lzf | 746 | -12% | +75% | +113% | 10.36 | +534% | +555% | +395%
------------------------------------------------------------------------------------------------------------
hdf5_gzip | 419 | -51% | -2% | +20% | 17.23 | +954% | +989% | +724%
------------------------------------------------------------------------------------------------------------
plt.clf()
fig = plt.figure(figsize=(12, 8), dpi=120)
plt.xlabel("File size [MB]")
plt.ylabel("Read time [s]")
plt.title("DAT, EVT2 and EVT3 encodings (chunked file)")
# Expelliarmus
for encoding in encodings:
plt.scatter(data["expelliarmus"][encoding]["fsize"], data["expelliarmus"][encoding]["chunked"], marker="o", s=240, color=exp_colors[encoding], label=f"expelliarmus - {encoding.upper()}")
# Other softwares.
for sw in softwares[:-1]:
plt.scatter(data[sw]["fsize"], data[sw]["chunked"], marker=sw_markers[sw], s=240, color=sw_colors[sw], label=sw)
plt.legend()
plt.show()
<Figure size 432x288 with 0 Axes>
if SAVE_RESULTS:
pickle.dump(data, open("./benchmark.pk", "wb"))